 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState of NLP in Kenya: A Survey
Oct 13, 2024


Kenya, known for its linguistic diversity, faces unique challenges and promising opportunities in advancing Natural Language Processing (NLP) technologies, particularly for its underrepresented indigenous languages. This survey provides a detailed assessment of the current state of NLP in Kenya, emphasizing ongoing efforts in dataset creation, machine translation, sentiment analysis, and speech recognition for local dialects such as Kiswahili, Dholuo, Kikuyu, and Luhya. Despite these advancements, the development of NLP in Kenya remains constrained by limited resources and tools, resulting in the underrepresentation of most indigenous languages in digital spaces. This paper uncovers significant gaps by critically evaluating the available datasets and existing NLP models, most notably the need for large-scale language models and the insufficient digital representation of Indigenous languages. We also analyze key NLP applications: machine translation, information retrieval, and sentiment analysis-examining how they are tailored to address local linguistic needs. Furthermore, the paper explores the governance, policies, and regulations shaping the future of AI and NLP in Kenya and proposes a strategic roadmap to guide future research and development efforts. Our goal is to provide a foundation for accelerating the growth of NLP technologies that meet Kenya's diverse linguistic demands.
Textual Augmentation Techniques Applied to Low Resource Machine Translation: Case of Swahili
Jun 12, 2023In this work we investigate the impact of applying textual data augmentation tasks to low resource machine translation. There has been recent interest in investigating approaches for training systems for languages with limited resources and one popular approach is the use of data augmentation techniques. Data augmentation aims to increase the quantity of data that is available to train the system. In machine translation, majority of the language pairs around the world are considered low resource because they have little parallel data available and the quality of neural machine translation (NMT) systems depend a lot on the availability of sizable parallel corpora. We study and apply three simple data augmentation techniques popularly used in text classification tasks; synonym replacement, random insertion and contextual data augmentation and compare their performance with baseline neural machine translation for English-Swahili (En-Sw) datasets. We also present results in BLEU, ChrF and Meteor scores. Overall, the contextual data augmentation technique shows some improvements both in the $EN \rightarrow SW$ and $SW \rightarrow EN$ directions. We see that there is potential to use these methods in neural machine translation when more extensive experiments are done with diverse datasets.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023



In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021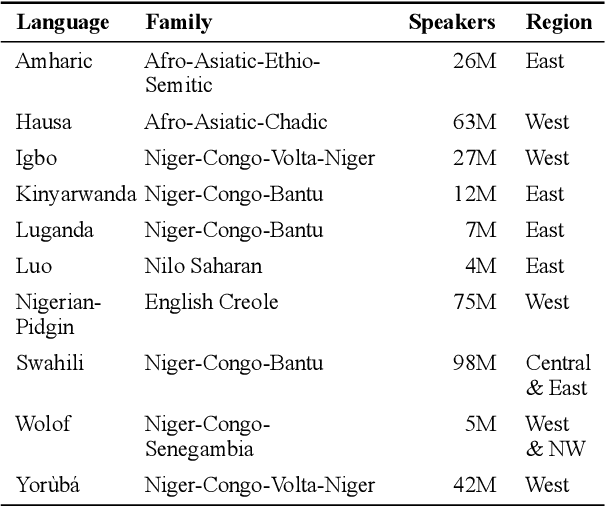

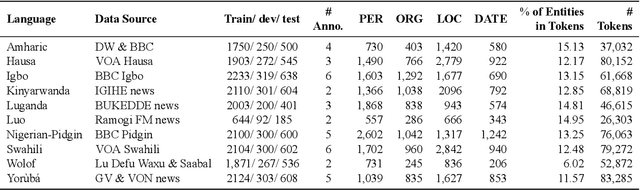
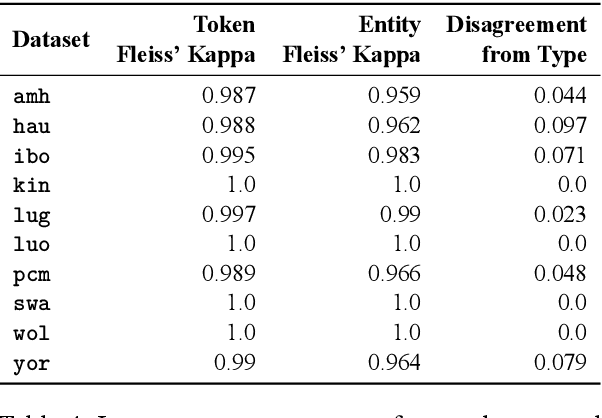
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.